【Meta社】オープンソースの音声・音楽生成AI「AudioCraft」をリリース!

Meta社(旧フェイスブック)が、テキスト入力から高品質な音楽や効果音を生成できるオープンソースの音声・音楽生成AI「AudioCraft」をリリースした。
この記事では、「AudioCraft」に関する最新情報をどこよりも詳しく解説します。
目次
音声・音楽生成AI「AudioCraft」とはなにか?
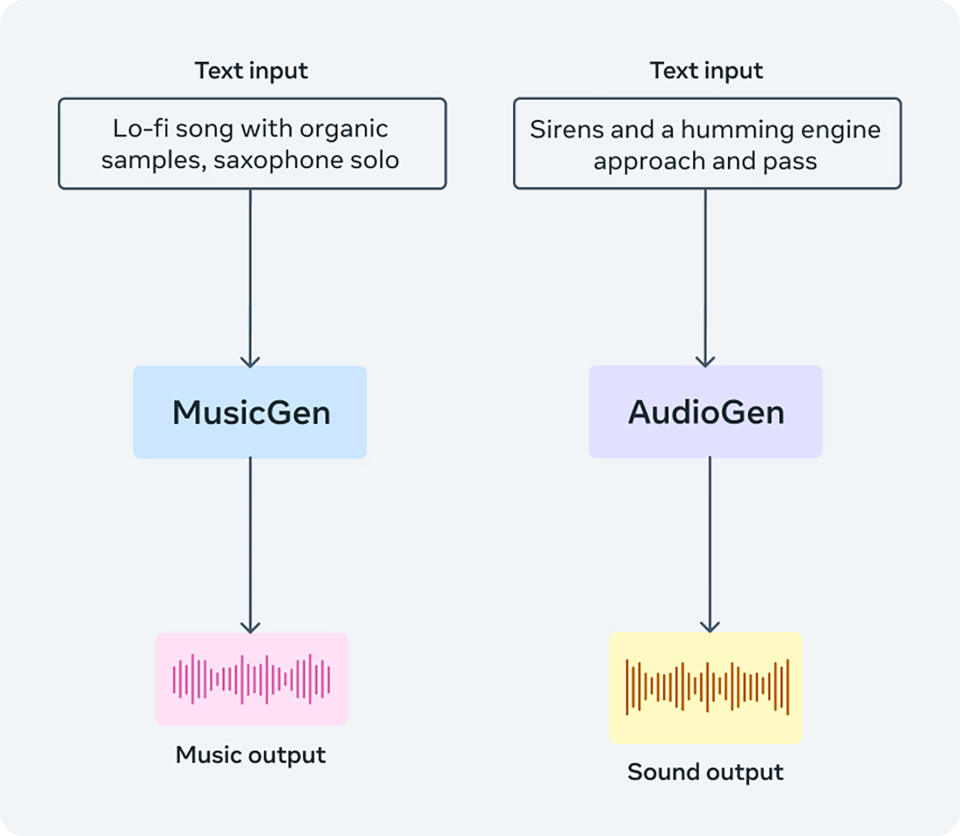
AudioCraftは、
1.MusicGen(音楽生成AI)
2.AudioGen(音声生成AI)
3.EnCodec(音声処理)
の3つのモデルで構成されており、音楽やオーディオの生成・圧縮などの機能を持っている。
Metaによると、AudioCraftは過去数年間に同社内で開発された生成AIの成果をまとめたもので、研究者や開発者がさらなる研究・開発の基盤として利用できるようオープンソースで公開した。
音楽家やクリエイター向けのツールとしても活用できる可能性がある。
1.MusicGen(音楽生成AI) : テキストからの高品質音楽生成を実現
AudioCraftで最も注目されるのが、MusicGenと呼ばれるモデルだ。
これは、テキスト入力から高品質な音楽を生成することができる。
Metaによると、MusicGenは同社が所有し、特別にライセンスを取得した2万時間分の音楽データセットでトレーニングされている。
通常のテキスト言語に変換しやすいMIDI(楽器の演奏データ)が中心とのこと。
訓練データセットには、様々な楽器、テンポ、長さの音楽が含まれ、ポップ、ロック、ジャズ、クラシックなど多様なジャンルを網羅しているそうだ。
Metaが示したサンプルを聞く限り、ピアノ、ギター、合唱などの自然な音色がテキストから生成されており、楽器の種類や速度を指定することもできた。
以下はMetaの公式X(Twitter)アカウントで公開されている、MusicGenによって生成された音楽です。
従来のtext-to-speechは自然な音声生成が難しく、音楽においては音色や響きの再現が課題とされてきた。MusicGenが高度な音楽生成を可能にしたことで、音声合成としての可能性が大きく広がったと期待されている。
研究者からは、単に楽器の音を生成するだけでなく、テキストからメロディやコード進行を作曲できる能力は、人間の創造性を超える可能性があるとの指摘もある。
一方で、トレーニングデータに偏りがあることで、出力結果にも偏りが出てしまう可能性が懸念される。
Metaもこの課題は認識しており、データセットの改善に取り組む必要があるとしている。
2.AudioGen(音声生成AI):環境音や効果音の生成にも対応
MusicGenに加え、AudioGenはテキスト入力から環境音や効果音を生成するモデルだ。
Metaが公開した事前訓練済みのAudioGenは、パブリックドメインの効果音データセットで学習されている。
以下のMeta公式ブログで、犬の吠え声、サイレン、ドアをノックする音といった音声がテキストからリアルに生成できるデモが公開されている。
参考:Meta公式ブログ

AudioGenによってゲームやVRコンテンツ制作などで必要な効果音を手軽に作れるようになることが期待されています。
3.EnCodec(音声処理) : 音声圧縮・デコードで音質改善
3つ目のEnCodecは、Metaが以前から研究していた音声圧縮アルゴリズムだ。
通常、音声データを圧縮すると音質が低下するため、AIで情報を復元するデコーディング処理を行う。
今回のEnCodec v2では、音質の劣化がより抑えられるよう改良されている。
MusicGenで生成した音楽やAudioGenの効果音を扱う際に、ファイルサイズを小さく保ちながら高音質を維持できるため、AudioCraft全体の品質向上に寄与する。
音楽業界からは著作権侵害への懸念の声も
ただし、機械学習モデルが既存の著作権音楽を解析することでトレーニングされる仕組みから、音楽業界からは著作権侵害への懸念の声も上がっている。
例えばスポティファイは昨年、70年代の楽曲を入力データに利用したとして訴訟を起こされた。裁判所は、人間の音楽家が曲を作曲するのと同じようにAIも著作権法の対象となり得るとの判決を下している。
MetaもMusicGenのトレーニングに自社ライセンスの音楽を利用しており、権利処理に配慮している様子だが、万全とは言い切れないだろう。
研究者からは、古典音楽などパブリックドメインの楽曲を入力データにすることで、この問題はある程度回避できるとの指摘もある。ただし、音楽のジャンルや様式に偏りが出てしまうリスクもある。
Metaも音楽データセットの偏りを認めており、オープンソース化により多様なデータを取り込んで改善していきたいとしている。
AIによる音楽生成は近年注目を集めている分野だ。
グーグルも今年、MusicLMと呼ばれる大規模言語モデルを元にした音楽生成AIを発表。ただしこちらは研究者向けに限定公開されている。
一方、ミュージシャンのドレイクらがAIを使って新曲を作ったと発表したが、すぐに削除される騒動もあった。
メタのAudioCraftが、どのように音楽シーンにインパクトを与えていくのか注目される。
データとアルゴリズムの透明性確保が課題に
そもそも、AIがどのようなプロセスで音楽を生成しているのか不透明感も指摘されている。
結果として聴こえてくる音楽自体はオリジナルとは言え、人間の創作活動を置き換える存在となりかねないといった声もある。
Metaは公開することで開発プロセスの透明性を高められるとしているが、データとアルゴリズムの在り方をめぐっては、今後も議論が必要とされそうだ。
一方で、音楽著作権協会(JASRAC)は、過去にAI作曲システムを活用した楽曲提供の実証実験を行うなど、前向きな姿勢も示している。
AIと人間クリエイターの共創を模索
音楽業界全体としては、AIを活用しつつ人間の創造性が失われないようなバランスが重要視されている。
すでに一部のミュージシャンは、AIにメロディやコードのアイデアを生成させ、そこから人間が編集・作曲するといった試みを始めている。グライムスなども、AIのサポートを得ながら作詞・作曲できる可能性に期待感を示している。
Metaも「AudioCraftがプロの音楽家の新しい楽器となり、人間とAIの共創を実現できる」と述べている。
ただし、技術的な側面だけでなく、創作の在り方そのものをめぐる倫理的な議論も必要とされているのが現状だ。
シンセサイザー登場の再来に期待も
歴史的に見て、新しい楽器やテクノロジーの登場は多くの場合、既存の音楽シーンを刷新してきた。
例えばシンセサイザーの発明は、従来のアコースティック楽器にはない新たな音楽表現を切り拓いた。EDMやテクノポップといったジャンルは、シンセサイザーなくしては存在し得なかっただろう。
AudioCraftについてメタは、そのような「新しい楽器の誕生」と表現している。音楽表現の可能性を大きく広げるイノベーションになり得るとみている。
一方で、単に既存の音楽を模倣するだけで終わってはイノベーションとは言えないという声もある。テクノロジーをどのように音楽文化に取り入れていくかが鍵を握るだろう。
プロの音楽家にも使い勝手重視を
メタは今後、AudioCraftをプロの音楽制作現場でも使いやすくする改善に取り組むとしている。
簡単なテキスト入力から音楽が生成できる点は優れているが、作詞・作曲にはより詳細なパラメータ制御が必要不可欠だ。テンポ、コード、音程といった要素を細かく指定できるインターフェースが求められる。
また、高品質な音源や編集機能を追加することで、プロ向けの音楽制作ツールとしての完成度を高められる可能性もある。作曲のアイデア出しから完成までを一貫して支援できることが望ましい。
さらに、作曲以外の音楽プロデュース領域への応用も期待される。楽曲の混合やマスタリング、音声修復などで活用することで、制作工程全体を強力に支援できるだろう。
AudioCraftを研究者向けにカスタマイズも可能に
AudioCraftはオープンソースで公開されているため、研究者や開発者が自由にカスタマイズできるのも大きな特徴だ。
メタは、自社の固有技術を集約しつつ、研究コミュニティに還元する形を取った。
プラットフォームとしての汎用性を高め、多様な応用が生まれることを期待している。
例えば、独自のデータセットで訓練し直すことで、特定の楽器やジャンルに特化したモデルを開発できる。あるいは、音楽以外の音声生成タスクに転用することも可能だ。
既存の成果を基に、さらなるイノベーションを促進するという役割がAudioCraftには期待されている。ソフトウェアライブラリとして音声・音楽分野で幅広く活用されていくことになりそうだ。
音声UIやメタバースでの応用も期待される
将来的には、メタが提供する各種サービスでAudioCraftが活用されることも予想される。
例えば、社内で開発が進められているVR空間「メタバース」内の背景音楽や効果音を動的に生成することが考えられる。ユーザーの行動に合わせたリアルタイムのサウンドデザインが可能になる。
音声UIの分野でも、生成音声の自然性と表現の幅を広げることが期待できる。テキスト入力からの高品質な音声合成は、音声アシスタントの改善に活用できる。
さらに、メタが提供する広告プラットフォームにも応用の余地がある。テキスト広告を読み上げる音声の品質向上や音声コンテンツの自動生成が可能になる。
各国の言語・文化的な違いにも対応できるか
一方で、メタのサービスがグローバルに提供されていることを考えると、言語の壁は大きな課題となり得る。
音声合成の精度は言語によって差があるのが実情だ。MusicGenも主に英語の音楽で訓練されていると見られ、他言語への対応が課題になりそうだ。
例えば、日本語では言葉のアクセントに多様性がある。音楽においても日本語ラップのように、言葉のリズムが重要なジャンルが存在する。こうした場合、単なる文字から音声への変換では不十分だ。
また、音楽の在り方そのものが文化によって異なる。インド音楽の微分音は、西洋的な音階だけでは表現できない。日本の囃子もそうした例だ。
Metaは既に、多言語対応の大規模言語モデルM2M-100の研究を進めている。
AudioCraftについても、言語・文化の壁を越えられるような枠組みが求められるかもしれない。
いずれにせよ、今後の動向が期待される。