【歴代最高性能】Stability AI、日本語LLM「Japanese StableLM Alpha」を公開!

画像生成AIで有名な「Stable Diffusion」などを開発するStability AIの日本法人Stability AI Japanは、日本語LLM「Japanese StableLM Alpha」の2つのモデルを開発し、2023年8月10日に公開しました。
複数の日本語タスクを用いた性能評価において、一般公開されている日本語向けモデルで最高の性能を発揮したといいます。
この記事では、日本語LLM「Japanese StableLM Alpha」についてわかりやすく解説するとともに、最近注目される日本企業による国産の日本語LLMの開発動向について最新情報を紹介します。
目次
日本語LLM「Japanese StableLM Alpha」を公開
画像生成AI「Stable Diffusion」などを開発するStability AIの日本法人Stability AI Japanは、日本語LLM「Japanese StableLM Alpha」の2つのモデルを2023年8月10日に公開しました。
- 70億パラメータの日本語向け汎用言語モデル「Japanese StableLM Base Alpha 7B」
- 指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」
汎用言語モデル「Japanese StableLM Base Alpha 7B」の概要
「Japanese StableLM Base Alpha 7B」はウェブを中心とした大規模なデータを用いてテキスト生成を学習したモデルです。
学習データは主に日本語と英語で、それに加えソースコードが約2%含まれています。
学習はのべ7500億トークンで行われ、学習データにはオープンデータセットに加え、独自のデータセットが含まれているとのことです。
モデルはHugging Face Hub で公開されており、商用利用可能なApache License 2.0での公開となります。
指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」の概要
「Japanese StableLM Instruct Alpha 7B」は汎用言語モデルに対し追加学習を行い、ChatGPTのようにユーザーの指示に回答できるようにしたモデルです。
追加学習には Supervised Fine-tuning (SFT) を採用しており、複数のオープンデータセットを利用することで高い性能評価を実現したといいます。
モデルはHugging Face Hub で公開されていますが、「Japanese StableLM Instruct Alpha 7B」については研究目的で作成されたモデルであり、研究目的での利用に限定(商用利用不可)した公開ということです。
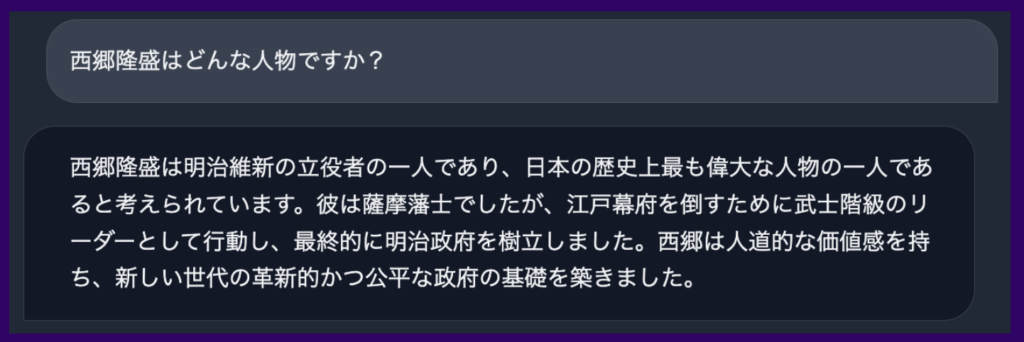
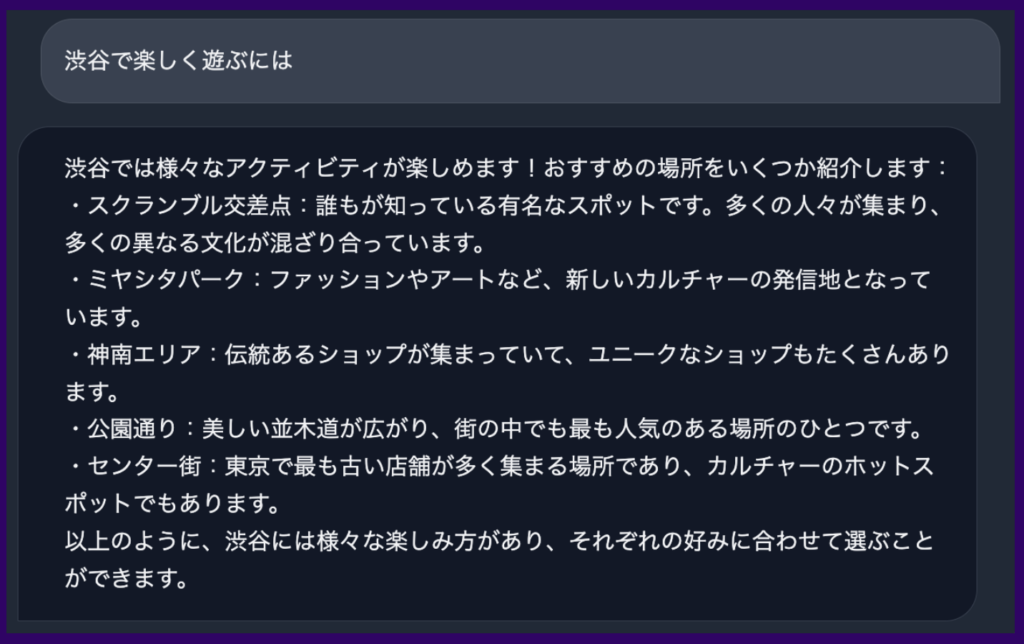
▼以下は同社が公開した「Japanese StableLM Instruct Alpha 7B」による実際の回答事例です。正確で自然な日本語で回答されていることが確認できます。
性能評価で日本語LLMとして歴代最高性能
EleutherAI の lm-evaluation-harness に よって2つのモデルの性能評価が行われました。
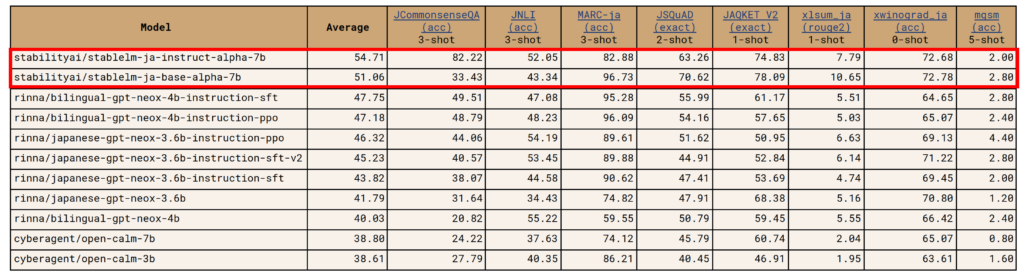
日本語言語理解ベンチマーク(JGLUE)のタスクを中心として、文章分類、文ペア分類、質問応答、文章要約などの合計8タスクで評価を行ったところ、Japanese StableLM Instruct Alpha 7B のスコアは54.71と、公開されている日本語LLM(rinnaやサイバーエージェントが開発する日本語LLM)に比べ、高いスコアを達成したといいます。
▼以下はrinnnaやサイバーエージェントなどの日本語LLMとの性能評価(総合評価)の比較結果。他の日本語LLMより平均10ポイント以上高いスコアを出していることが確認できます。

▼評価項目の8タスクごとの性能評価結果。
使用方法
モデルを実際に試したい場合は、以下の記事を参考にしてみるといいでしょう。
参考1:Japanese StableLM Base Alpha 7BをGoogleColabで試してみる
参考2:Japanese StableLM AlphaをDockerで動かす
国産の日本語LLMの最新動向
大規模言語モデル(LLM)の開発は、OpenAI、Google、Metaなどの欧米プレイヤーが先行し、日本企業は遅れを取っていましたが、日本でも複数の企業による国産の日本語LLMの開発が進んでいます。
2023年5月にはrinnnaやサイバーエージェントが日本語LLMを公開、7月にはNEC、8月にストックマークやStability AI Japanが日本語LLMの開発を発表、ソフトバンクや富士通は国産LLMを開発する計画を公表しています。
今後の日本語LLMの開発が注目されます。
▼日本語LLMの開発事例
| 開発会社 | 公開 | 特長 |
| Stability AI Japan | 23年8月 | 70億パラメータの最高性能の日本語LLM |
| rinna | 23年5月 | 36億パラメータのGPT言語モデル |
| サイバーエージェント | 23年5月 | 最大68億パラメータの日本語LLM |
| NEC | 23年7月 | 130億パラメータで世界トップクラスの日本語性能 |
| ストックマーク | 23年8月 | 最近の話題にも詳しい14億パラメータの日本語LLM |
| ソフトバンク | 未定 | 日本語に特化した国産LLMの研究開発のために新会社を設立 |
| 富士通 | 未定 | スーパーコンピュータ「富岳」を活用した国産LLMを開発 |